

Alors que s'est tenue la semaine dernière en Hongrie la sixième école d'été sur le calcul en grille, peu de gens savent exactement de quoi il en retourne. Ces problèmes très pointus n'intéressent qu'une poignée d'individus surdiplômés, pourriez-vous même penser. Pourtant, plusieurs d'entre vous (ou plutôt vos ordinateurs) pratiquent ce genre de calculs tous les jours. Les Seti@Home, Folding@Home et autre FightAids@Home sont en effet quelques-uns des exemples les plus connus de Grid Computing.
Le calcul distribué, partie du calcul intensif
Qu'est-ce exactement que le calcul en grille ? C'est une partie de ce que l'on appelle le calcul intensif, qui est pratiqué par les scientifiques et quelques industries privées pour venir à bout de problèmes qui nécessitent de très grandes ressources informatiques, tant au niveau du temps de calcul que de la capacité de stockage.
Tera 10, le supercalculateur du CEA
Traditionnellement, les recherches utilisant du calcul intensif s'effectuent sur des supercalculateurs ou des grappes (ou clusters) de dizaines, voire de centaines d'ordinateurs uniquement dédiés à ces opérations. Le problème de ces systèmes est leur coût, tout d'abord, mais aussi leur puissance toute relative comparée au nombre de personnes les utilisant, chacune d'entre elles proposant à la machine des calculs qui peuvent durer de plusieurs heures à plusieurs semaines. Conséquence : la plupart du temps, la file d'attente est longue et ralentit considérablement la progression des scientifiques.
Une chaîne d'éléments distants

Plusieurs éléments composent cette chaîne de calcul :
- la source des informations en est le premier maillon. Ces sources peuvent être de formes multiples : télescopes, détecteurs de particules, ordinateurs (pour les simulations numériques)... ;
- ces données transitent ensuite par le cerveau qui les centralise, les distribue et optimise le système afin de mieux répartir la charge selon les disponibilités de chacun. Ce cerveau est appelé le « courtier en ressources » et nous reviendrons sur son rôle par la suite tant il est important ;
- toutes ces informations passent par le réseau, élément à part entière de la chaine, et dont les propriétés (notamment de vitesse) comptent pour beaucoup dans la progression des calculs ;
- enfin une application installée par vos soins sur votre ordinateur ferme cette chaîne. Son rôle est d'envoyer un message pour spécifier qu'il est prêt à calculer, de réceptionner les informations envoyées par le serveur, d'effectuer le calcul demandé et bien sûr d'expédier en retour les résultats obtenus.
Qui est le cerveau de l'opération ?
Le travail du courtier en ressources, lui, est autrement plus complexe. Il va en effet devoir constamment envoyer et recevoir des données vers ou en provenance de n'importe quel endroit du monde, repartir les calculs selon les ressources de calcul et de stockage disponibles (et pour cela, établir un traitement statistique de celles-ci). C'est autour de lui que s'organise toute la chaîne. Le travail de répartition des calculs, notamment, est le plus délicat : en effet, il est plus délicat de travailler sur une grille externalisée que sur une grappe de nœuds à cause de l'hétérogénéité des machines. L'optimisation de la tête pensante de ce réseau de calcul est donc l'un des domaines de recherche les plus prisés du moment.Le fonctionnement client-serveur n'est cependant pas le seul à exister dans le calcul distribué qui s'est également inspiré de ce qui existait dans des domaines d'échange de données en général. Ainsi la technologie peer-to-peer peut également s'appliquer à ce style de réseau.
Quid de la sécurité ?

D'un tout autre point de vue, qu'en est-il de la sécurité des bénévoles qui acceptent qu'un flux important de données entre et sorte chaque jour de leur machine ? En avril 2003, le programme Seti@Home avait souffert d'une faille de sécurité relativement importante. La question de la sécurité est donc un paramètre essentiel du calcul distribué dont les concepteurs des logiciels « courtier en ressources » doivent impérativement tenir compte.
Panorama des différents projets
Il existe aujourd'hui de nombreux projets utilisant le calcul distribué, preuve de l'engouement des chercheurs (et de quelques industriels) pour cette nouvelle forme de calcul. Retraçons-en l'historique de façon chronologique.Projets de chiffrement
Ce sont les premiers à apparaître à la fin des années 90. Ils concernaient des défis cryptographiques dont le but était (pour le premier d'entre eux) de prouver qu'un algorithme de chiffrement sur 56 bits que le gouvernement américain voulait imposer comme standard n'était pas fiable. Après DES (que nous venons d'évoquer) ont suivi DES II et RC5, tous lancés par les laboratoires RSA. D'autres projets ont également vu le jour, visant à découvrir le plus grand nombre premier (GIMPS), à factoriser les nombres de Fermat ou des nombres composites. Bref, des sujets bien trop complexes pour passionner le grand public.SETI@Home, là où tout commence
C'est au début de l'année 1999 que le calcul distribué a pris une ampleur mondiale, avec le fameux SETI@Home (pour Search for Extraterrestrial Intelligence). Les concepteurs de ce projet n'avaient peut-être pas imaginé que le sujet qu'ils allaient populariser rendrait un fier service à la communauté scientifique, puisqu'en terme de calcul distribué on peut véritablement parler d'un avant et d'un après SETI@Home. Pour ceux qui ne savent pas de quoi il est question, petit rappel. Ce
La force du projet SETI@Home, outre son but qui peut légitiment passionner un très large public, est d'avoir développé un client fonctionnant pendant l'écran de veille de Windows et affichant quelques jolis graphiques qui rappellent à l'internaute que son ordinateur participe activement à la recherche.
La science s'engouffre dans la brèche
Des entreprises comme EDF ou EADS ont également déjà mis à profit la technologie du calcul distribué pour effectuer des simulations numériques pour l'A380 ou la fusée Ariane par exemple. Évidemment, aucun client « grand public » n'a été mis à disposition et pour cause : le secret industriel serait probablement mis à mal par une telle pratique.
Un client pour les rassembler tous ?
La multitude de projets déclinés autour du calcul distribué a cependant un défaut de taille, celui de disperser les ressources. Car s'il est certain que la puissance disponible est gigantesque, elle n'est pas inépuisable. Par ailleurs, il est difficile de faire cohabiter deux programmes dans l'écran de veille de Windows. Enfin, il devient difficile pour l'internaute de savoir à quelle cause vouer son ordinateur.
Deux acteurs du calcul distribué

Clubic : Corentin Chevalier, vous vous occupez de diffuser largement (via votre site et vos déplacements dans des conférences) les nouvelles possibilités offertes par le grid computing. Votre auditoire est-il davantage du domaine public ou du domaine privé ?
Corentin Chevalier : Tout d'abord il faut que je vous parle du grid computing, ou la « Grille ». Comme le Web, la Grille est un service permettant de partager quelque chose sur l'Internet, sauf qu'ici il n'est plus question d'information mais de puissance informatique et de la capacité de mémoire. Mais la Grille fait beaucoup plus qu'établir une simple communication entre les machines. Son objectif ultime est de transformer le réseau mondial des ordinateurs en une ressource immense et unique de capacité de traitement.

Portion du LHC, au CERN
Un exemple concret est le calcul volontaire, ou distribué. Vous connaissez tous Folding@home ? Et bien il y a des dizaines de projets comme celui-ci (voir ce lien). Ces informations servent aussi à informer et impliquer nos politiciens (à un niveau Européen ou mondial) dans ces recherches et ces projets, afin qu'ils sachent pourquoi ils vont voter des budgets. »
Clubic : Des entreprises ont éventuellement pris contact avec vous pour des formations ou des demandes de renseignement ? Si oui, lesquelles ?

Clubic : Comment jugez-vous l'évolution de l'intérêt des acteurs du calcul intensif dans le domaine du grid computing ?
CC : De notre point de vue, il grandit à vue d'œil ! D'un point de vue plus général, je dirai que ce domaine a été découvert par les médias il y a cinq ans. Aujourd'hui, cette couverture médiatique est moins présente, car le grid computing est moins nouveau. Par contre infiniment plus de monde l'utilise, que l'on parle de scientifiques ou du grand public. Il y a maintenant même des écoles dédiées à ce domaine !
Clubic : Quelles sont les solutions pour arriver au rêve de la Grille absolue comme vous l'évoquez sur votre site ?

Ensuite, et bien il y a les centaines de projets autour du grid computing, dans le monde entier : l'Europe, les USA, l'Amérique en général, l'Asie, mais aussi l'Afrique ! Chacun amène différents projets dans différents domaines, et ils contribuent chaque jour à faire grandir la Grille. Encore une fois, Folding@Home est un projet, et il en existe des centaines !
Enfin, le rêve absolu, comme vous l'indiquez, passe par des étapes très importantes, telles que la standardisation. Sans celle-ci, comment imaginer une coopération mondiale de tous les ordinateurs ?
Clubic : Quels sont les moyens pour arriver à convaincre les particuliers à partager leurs ressources lorsqu'elles ne sont pas utilisées totalement ?
Le tout premier moyen ne peut être que la communication. Ensuite je ne pense pas que nous ayons à convaincre les gens d'utiliser par exemple un programme de calcul volontaire : ils le font d'eux-mêmes, car quoi de plus merveilleux de savoir que vous aidez activement à la recherche contre le cancer, le sida, ou à mieux comprendre notre univers ! Car c'est possible dès aujourd'hui ! Vous savez, je crois que de nos jours, tout le monde se rend compte à son niveau que si nous continuons comme ça, nous allons droit dans un mur... Alors quoi de mieux que de préparer l'Avenir, avec un grand A ?
Clubic : Finalement, y a-t-il des perspectives grand public dans le grid computing, une sorte de mise en commun des ressources mondiales pour le particulier ?
CC : Bien sur ! Mais ces perspectives ne sont plus du domaine du futur, mais une réalité aujourd'hui. Vous avez un exemple : le calcul distribué. C'est un outil formidable qui change complètement la donne scientifique. Quant à dire ce que nous apporteront ces technologies dans le futur, c'est plutôt difficile. Vous savez, c'est à l'endroit où je travaille, c'est à dire au CERN, que l'Internet a été inventé. A l'époque, il était difficile de dire ce qui allait réellement en découler. Mais je pense qu'il y a 15 ans, ils sentaient que c'était quelque chose d'énorme ; et bien je peux d'ores et déjà vous dire que le grid computing est quelque chose d'énorme pour la communauté scientifique.


Clubic : Quels sont les sujets de recherche qui ont nécessité le recours à du calcul distribué ? Avez-vous développé vous-même vos applications ?
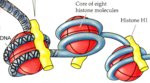
Richard Lavery : Nous avons exploité le calcul distribué dans deux projets de recherche. Le premier, le projet Decrypthon, concerne la recherche des interactions binaires au sein d'un ensemble de protéines. Ceci implique de tester l'interaction potentielle de chaque paire de protéines avec un logiciel d'amarrage conçu par Sophie Sacquin-Mora dans mon ancien laboratoire à Paris. Ce logiciel tente d'optimiser l'énergie d'interaction en partant de plusieurs centaines de milliers d'agencements des deux partenaires.
Clubic : Vos logiciels sont-ils distribués au grand public ou dans un cadre restreint ?

Clubic : Que vous apportent les contributions externes face aux ressources internes ?
RL : Les deux projets qui nous concernent ne seraient tout simplement pas réalisables en terme de ressources informatiques sans l'apport du calcul distribué sur des milliers de processeurs.
Clubic : Les résultats ne servent-ils que la recherche publique ?

Clubic : Quelles évolutions vous semblent possibles sur le principe de la grille en général ?
RL : Les applications dites « embarrassingly parallel » (impliquant des multiples tâches indépendantes) sont parfaitement adaptées aux grilles actuelles. La disponibilité de milliers de processeurs ouvre la voie à de multiples applications en biologie (conception de médicaments, génomique comparatif, biologie systémique, etc.).
Les différentes technologies utilisées
Après avoir vu les principaux projets en cours et quelques exemples concrets des applications possibles du calcul distribué, qu'en est-il de la partie matérielle ? Si les calculs effectués par nos machines le sont généralement par leur processeur, la carte graphique et même une console de jeu peuvent également jouer un rôle intéressant. En effet, de nombreux projets de calcul distribué utilisent fort logiquement le calcul parallèle qui avantage certains composants face à d'autres. Explications.L'incontournable CPU

La Playstation 3 et son processeur Cell
Si un processeur peut facilement traiter une simple addition (ou d'autres opérateurs plus complexes comme le logarithme ou l'exponentielle), qu'en est-il de plusieurs milliards d'additions simultanées ? Il existe une autre façon de résoudre un problème dont le nombre d'opérations est particulièrement important et dans lequel ces opérations sont indépendantes : il s'agit de la parallélisation.La plupart des calculs graphiques sont parallélisables, c'est-à-dire que l'on peut les découper en une série d'opérations indépendantes que l'on peut traiter simultanément. Un plus grand nombre d'unités de calcul (moins complexes que celles d'un CPU) parviennent alors à résoudre le problème plus rapidement que ne le ferait un processeur. En contrepartie, la quantité de mémoire cache est moindre que pour un CPU. C'est le facteur limitant dans ce type d'architecture, car la transmission de données de la mémoire vive vers le processeur est plus lente que si les instructions et/ou les données sont stockées dans la mémoire cache.
Un processeur Cell est un savant mélange d'unités de calcul capables à la fois de résoudre rapidement un jeu d'instruction complexe et d'appliquer à de nombreuses données une opération simple et répétitive. C'est lui qui équipe la dernière console de Sony, la Playstation 3, dont les performances ont énormément apporté au projet Folding@Home en terme de puissance.
Le GPU, nouveau venu dans la bataille
Le GPU (pour Graphics Processing Unit) est la logique de parallélisation poussée à l'extrême : ici, les unités de calcul sont très nombreuses, toutes destinées à du calcul « simple » et la mémoire prend très peu de place. Ces éléments sont donc tout à fait véloces pour ce qui est du calcul parallèle (comme le rendu 3D) et particulièrement peu adaptés aux opérations plus complexes. C'est toutefois moins vrai pour les dernières générations de cartes graphiques, que ce soit chez NVIDIA ou chez AMD, puisqu'elles embarquent quelques unités de calcul programmables et propres à effectuer d'autres tâches plus généralistes que les simples rendus 3D. C'est ce qu'on appelle le GP-GPU (general purpose GPU).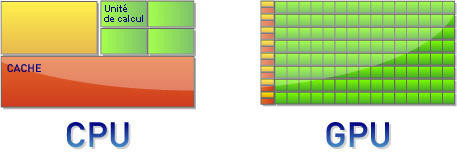
La quantité de mémoire cache est moindre dans un GPU que dans un CPU
NVIDIA et son API CUDA ou AMD avec le Brook+ proposent deux langages de programmation permettant aux développeurs d'utiliser facilement le potentiel de leurs cartes graphiques. C'est ainsi qu'une application comme Folding@Home peut utiliser une (ou plus ?) cartes NVIDIA ou AMD au lieu du traditionnel CPU. Nous verrons à la page suivante les performances de chacun.
Quelques chiffres à titre de comparaison
Vous l'avez compris, un processeur comme le Cell ou même des cartes graphiques peuvent être à leur avantage face à un CPU « classique », même les plus puissants comme le Core Quad d'Intel. Pour exprimer une puissance de calcul, la grandeur utilisée traditionnellement est le FLOP (pour FLoating point Operations Per Second), qui représente le nombre d'opérations en virgule flottante (c'est à dire en chiffre réel) effectuées en une seconde. Pour exprimer ce dont sont capables les supercalculateurs actuels, quelques préfixes s'imposent : ainsi, le petaflops (qui représente un million de milliards d'opérations par seconde) est aujourd'hui l'unité de référence. C'est un supercomputer qu'IBM a vendu à l'armée américaine qui a passé cette barrière symbolique en mai dernier : le Roadrunner composé de 6 948 Opteron bicoeurs et de 12 960 processeurs Cell. A titre de comparaison, le processeur le plus puissant à l'heure actuelle, à savoir le Core Quad QX9775 d'Intel, développe « seulement » 51 gigaflops, tandis qu'une GeForce 8800 Ultra de chez NVIDIA en produit plus de dix fois plus à l'aide de ces 128 unités de calcul (qui ne sont pas comparables à celles présentes dans un CPU, rappelons-le).Mais le calcul distribué, de par le nombre d'ordinateurs qu'il utilise, bénéficie d'une puissance encore plus extraordinaire. Ainsi, l'ensemble des projets compris dans l'interface BOINC bénéficie actuellement de plus d'un petaflops de puissance, tandis que le très populaire Folding@Home est soutenu par plus de 2,5 petaflops.
Quelques tests pour en savoir plus
Nous avons vu qu'il existait plusieurs éléments capables d'effectuer calcul distribué : un CPU classique, une carte graphique ou une console de jeux sont trois possibilités différentes dont un projet comme Folding@Home a su tirer partie. Cette application possède en effet quatre clients distincts : le premier est destiné aux processeurs que vous connaissez, le second a été développé pour la Playstation 3 et son processeur Cell et deux autres versions concernent certaines cartes graphiques NVIDIA et AMD. C'est donc Folding@Home qui va nous permettre de voir de quoi sont capables les différents éléments. Ne vous méprenez pas toutefois : si les chiffres que nous allons vous apporter sont intéressants, ils restent incomparables pour la simple raison que le client est différent dans chaque cas.A chacun son client
Les clients pour CPU () ou pour GPU () sont disponibles dans notre logithèque. Les pilotes Catalyst se trouvent dans notre base de pilotes tandis que les Forceware de NVIDIA se trouvent quant à eux sur le site du constructeur (seuls les versions 174.55 et 177.35 sont compatibles avec CUDA à l'heure actuelle).Pour la Playstation 3 de Sony, vous pouvez trouver l'icône Folding@Home dans la colonne Réseau du menu de la console.
Quel résultat pour quel matériel ?
Sans vouloir, nous le répétons, comparer les performances de chacun, nous avons répertorié les scores réalisés par quatre éléments différents : un Core 2 Extreme QX9650 d'Intel (accompagné de 2 Go de DDR3 PC14400), une Radeon HD 4870 d'AMD, une GeForce GTX280 de NVIDIA et la Playstation 3 et son processeur Cell. Après avoir laissé tourner le programme 30 minutes, voici les scores réalisés par nos différents éléments :| Matériel | Intel Core 2 Extreme QX9650 | AMD Radeon HD 4870 | NVIDIA GeForce GTX 280 | Playstation 3 |
| Score | 3 492 (4 x 873) | 1 730 | 6 582 | Environ 900 |
Premier enseignement : la version graphique du client Folding@Home n'est pas conçue pour faire fonctionner des processeurs multicœurs. Nous avons donc du installer la version console de cette application et lancer quatre fois le processus en définissant une affinité spécifique de chaque processus avec un cœur différent. Ce n'est pas forcément ce qu'il y a de plus simple...
Pour comprendre ces résultats, il faut savoir comment ils sont calculés. Lorsque vous exécutez le client Folding@Home, vous travailler sur des unités de calcul. Chacune d'entre elles rapporte un certain nombre de points et on peut juger de la faculté d'un élément à apporter une large contribution au projet en fonction du nombre de points par jour (PPD, Points Per Day). Le logiciel FAHMon estime ce nombre, même pour un temps effectif de calcul relativement court.
Comme nous le voyons dans le tableau, la carte graphique de NVIDIA est extrêmement doué pour ce client de calcul distribué. Notez par ailleurs que le client Folding@Home pour GPU ATI n'est pas encore complètement optimisé pour bénéficier de l'ensemble de possibilités de la carte graphique. Enfin les quatre cœurs de notre Core 2 Extreme QX9650 font mieux que le processeur Cell de la Playstation 3 (la valeur indiquée est celle communément admise pour la console de Sony). Notez toutefois que ce dernier est aussi puissant qu'un seul des coeurs de notre CPU Intel (qui réalise 873 PPD). Si 30 000 utilisateurs de la console de Sony avaient suffi à tripler la puissance (voir cette actualité : Folding@Home : la Playstation 3 impressionne) dédiée au projet, imaginez quels résultats seraient obtenus avec la mise à disposition du même nombre de GeForce GTX 280...
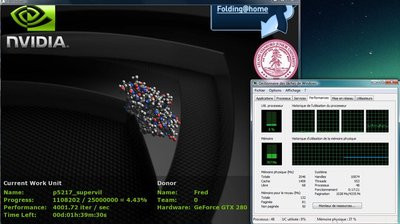
Comme vous pouvez le voir, le CPU n'est presque pas utilisé avec la version GPU de Folding@Home
Quelques informations supplémentaires sur Folding@Home
Les détracteurs du calcul distribué évoqueront sans doute la sécurité du système et le vieillissement prématuré du processeur s'il est constamment sollicité. Nous ne pouvons pas leur donner de mesure pour les rassurer dans ce domaine, même si le dernier argument semble assez fantaisiste, un processeur étant fabriqué pour fonctionner et non pour être au repos. En revanche, la consommation de mémoire vive en dehors des périodes de calcul, la bande passante utilisée lors des échanges et le surplus de consommation électrique sont trois inquiétudes que nous pouvons ici chiffrer. Évidemment, les valeurs que nous avançons sont spécifiques à notre machine d'une part, et au client (ici, Folding@Home) d'autre part.Lors de nos tests, nous avons relevé une consommation de mémoire vive hors période de calcul de 30 Mo pour le client graphique, valeur par ailleurs identique que lorsque les calculs s'effectuent. Cette occupation n'est pas excessive, inférieure à bien des logiciels tournant en tâche de fond. Folding@Home est donc une application relativement légère, à l'image de la plupart des autres clients de calcul distribué.

En ce qui concerne la consommation de bande passante, elle est quasiment invisible noyée dans une navigation classique. Enfin, la consommation électrique est également une donnée intéressante. Grâce à notre wattmètre, nous avons observé un accroissement de consommation 36 Watts (170 Watts durant les calculs avec notre QX9650 contre 125 Watts au repos). Un rapide calcul prenant en compte quatre heures d'utilisation par jour toute l'année durant et un tarif de 10,85 centimes le kilowatt-heure (en heures pleines) nous amène à un surcoût d'environ 7 euros sur votre facture d'électricité annuelle.
Questions et perspectives

- le développement de clients spécifiques à d'autres supports que le traditionnel CPU. Nous avons vu l'apport de la Playstation 3 pour Folding@Home ;
- l'augmentation des débits Internet pour le particulier, ce qui facilite l'échange de données et va permettre de délocaliser davantage d'informations à l'avenir.
Des progrès sont en effet possibles au niveau des clients tout d'abord (quelle galère pour lancer Folding@Home sur les quatre cœurs de l'Intel Core 2 Extreme QX9650 !), mais également au niveau du traitement de l'information, de la distribution des données, de l'équilibrage des charges, de l'ordonnancement des jobs... C'est donc aussi l'intergiciel (ou courtier en ressources), le cerveau de la chaîne, qui doit être amélioré afin d'optimiser l'ensemble de la chaîne.
Corentin Chevalier nous l'a dit : la communication est le seul moyen de motiver les volontaires à mettre à disposition de la science leurs ressources. Mais cette communication est-elle suffisamment efficace ? Par exemple, sait-on à qui profite réellement le calcul effectué sur votre machine ? Les résultats des calculs distribués sont-ils assez clairement affichés ? La nécessité de transparence devrait être strictement identique à celles des associations humanitaires ou caritatives qui récoltent nos dons en monnaie sonnante et trébuchante.
Une communication ainsi améliorée aiderait probablement les internautes à se sentir plus utiles et conserverait intact le réservoir de bonne volonté, l'intérêt de pouvoir faire de « l'humanitaire » sans bouger de chez soi étant réel pour un public assez large. Le travail de personnes comme notre premier interlocuteur est louable, mais il doit être réalisé de concert avec les scientifiques.
Ces derniers pourraient alors nous expliquer que si aucun résultat compréhensible pour le grand public n'est sorti de tels calculs, tous les efforts produits ont tout de même un intérêt indéniable, celui d'éliminer des pistes de recherches par méthode essai-erreur de manière très rapide.
Enfin, comme le suggère François Grey, spécialiste du calcul en grille, ne pas créer de véritables réseaux sociaux, capables de réunir les volontaires qui pourraient ainsi travailler de façon concertée ? Ce type de réseaux pourrait permettre de structurer les efforts communautaires qui règnent actuellement dans le calcul distribué et de maintenir ainsi l'émulation à un haut niveau.

- Venez discuter de cet article dans le forum
