
Le Web croule sous les données textuelles, audiovisuelles et graphiques. En 2008, environ 480 milliards de gigaoctets étaient disponibles sur Internet. Deux ans plus tard, ce volume a presque doublé ! Et cette évolution semble sans fin : selon le cabinet d'analyses Gartner, à l'horizon 2015, quelque trois milliards d'individus seront connectés et partageront des données, personnelles ou non, pour atteindre un total de huit Zo (Zettaoctets). Pour information, un Zo est égal à un milliard de To (Teraoctet), soit l'équivalent du volume stocké sur 250 milliards de DVD. Bienvenue dans l'ère du Big Data !
Il s'agit d'analyser ces milliards de données afin de dénicher l'information pertinente permettant de prendre la bonne décision. Cette activité représente un marché évalué à 3,2 milliards de dollars en 2010. Elle devrait croître de 39,4% par an pour atteindre 16,9 milliards en 2015 (source : étude IDC « Digital Universe ») ! Cette croissance ne se limite pas à l'analyse d'énormes volumes. Le marché de la gestion et de l'analyse de données est estimé à plus de 100 milliards de dollars et croît de près de 10% par an, soit environ deux fois plus vite que le marché global des logiciels.
Cette expression Big Data a été évoquée pour la première fois par le cabinet d'études Gartner en 2008. Quatre ans plus tard, la situation a considérablement évolué. Pour les entreprises, ces milliards de données sont à la fois une formidable source d'informations permettant de mieux connaître ses clients et les tendances de leur secteur d'activité (être capable de faire la différence entre le buzz ou l'épiphénomène et des « signaux forts ») et aussi de suivre l'évolution de ses concurrents.
5 heures par semaine passées à chercher des informations...
Mais cette volumétrie en perpétuelle croissance est aussi un double défi : technologique et économique. Dans l'univers de la gestion de l'information, trouver la donnée pertinente dans d'importants volumes structurées (bases de données, applications métier) est une activité maîtrisée. Mais la montée en puissance d'internet et la multiplication des appareils connectés à des réseaux (smartphones, tablettes mais aussi capteurs, compteurs électriques, bornes...) génèrent des données non structurées (emails, documents, fichiers, audio, vidéo, etc.).
Cette évolution génère des coûts élevés. Une étude d'IDC a indiqué que les employés perdent au minimum cinq heures par semaine à rechercher les informations utiles pour leurs activités quotidiennes, ce qui coûte aux entreprises entre 4 000 € et 16000 € par an et par employé.
Les solutions de Big Data doivent donc relever ces défis en tenant compte de la règle dite des 3V : volume, variété et vélocité.

Les 3 V du Big Data selon Teralytics
- Les volumes : confrontées à des contraintes de stockage, les entreprises doivent aussi gérer le tsunami des réseaux sociaux. Chaque jour, deux millions de vidéos sont ajoutées sur YouTube, 5 millions d'images sont mises sur Flirck, 300 millions de photos sont transférées sur Facebook et 140 millions de messages sont publiés sur Twitter !
La montée en puissance des réseaux sociaux a accentué cette production de données. Résultat, les volumes sont passés du téraoctet au pétaoctet, à cause de leurs types (vidéos, photos, sons...). Selon le cabinet McKinsey, les entreprises auraient stocké 7 exaoctets de données supplémentaires en 2010. Les solutions de Big Data doivent rendre accessible la masse de données intéressant leurs clients pour ensuite les analyser. Imaginez qu'un acteur comme Facebook indique emmagasiner 500 téraoctets de nouvelles informations chaque jour !
- La variété des sources : premièrement, l'époque où les entreprises s'appuyaient uniquement sur les informations qu'elles détenaient dans leurs archives et ordinateurs est révolue. De plus en plus de données nécessaires à une parfaite compréhension du marché sont produites par des tiers. Deuxièmement, les sources se sont multipliées : banques de données, sites, blogs, réseaux sociaux, terminaux connectés comme les smartphones, puces RFID, capteurs, caméras...
Les appareils produisant et transmettant des données par l'Internet ou d'autres réseaux sont partout, y compris dans des boîtiers aux apparences anodines comme les compteurs électriques. Par exemple, le Linky d'EDF transmet à distance quatre mesures par heure au gestionnaire du réseau et aux fournisseurs d'électricité. Auparavant, des agents EDF relevaient les consommations une fois par an... Les solutions de Big Data doivent donc être capables d'analyser de nombreuses sources d'informations dont certaines sont extérieures à l'entreprise et non maîtrisée par elle.
- La vélocité, ou l'obligation de prendre une décision pertinente très rapidement : à l'ère d'internet et de l'information quasi instantanée, les prises de décision doivent être rapides pour que l'entreprise ne soit pas dépassée par ses concurrents.
S'ajoute ensuite un dernier « V », celui de la visualisation : l'apanage des nombreux outils et suites dédiés au décisionnel.
Les besoins des entreprises
La montée en puissance des réseaux sociaux et du commerce électronique a encouragé le développement de solutions dédiées au Big Data. Logiquement, les premiers clients, et même les initiateurs, ont été les acteurs historiques de l'Internet (Yahoo !, Google...), ensuite les poids lourds du e-commerce (e-Bay, Amazon...) et enfin les réseaux sociaux (Facebook, Linkedin...).La seconde vague de clients comprend les acteurs de la grande distribution et des télécoms, mais aussi les organismes financiers. De grands groupes industriels tirent aussi des bénéfices des solutions de Big Data. Très peu de recherches peuvent en effet rapporter beaucoup d'argent à une entreprise. Avant de développer une nouvelle technologie et de la protéger en déposant des brevets, des multinationales s'appuient sur des technologies de Big Data pour vérifier qu'aucune de leurs filiales ne l'a déjà fait auparavant. De quoi économiser « des centaines de milliers d'euros », selon l'éditeur d'un moteur de recherche spécialisé dans le Business search.
L'exemple de ces multinationales montre que les solutions de Big Data doivent répondre aux besoins particuliers des entreprises.
- Marketing : développement du géo-marketing, du marketing comportemental... Une marque de sport peut souhaiter analyser les commentaires laissés sur ses pages Facebook et sur des blogs spécialisés et reconnus. L'analyse du comportement des internautes et du parcours de chacun des visiteurs d'un site est affinée par le Big Data. Ces études permettent en effet aux sites de préciser leur stratégie de segmentation de leurs visiteurs afin de réorienter en temps réel le contenu présenté. Elles permettent aussi de comprendre ce qui fait basculer l'internaute dans l'acte d'achat, en fonction des clics ou des formulaires remplis.
- Merchandising : optimisation des assortiments, des prix et des emplacements.
- Logistique : gestion des inventaires, optimisation de la logistique et des négociations fournisseurs.
- La réglementation : la gestion des risques ou de la fraude pour les banques ou la LCEN (Loi pour la confiance dans l'économie numérique) dans les télécoms par exemple nécessitent de stocker de très gros volumes de données pour assurer une traçabilité maximale mais aussi une réactivité dans l'analyse des données afin de faciliter le déclenchement d'alertes liées à des comportements suspects.
- La sécurité informatique : « L'âge du Big Data en sécurité est arrivé », affirme Eric Schwartz. Pour le RSSI de RSA, il est nécessaire d'avoir une approche de la sécurité tenant compte du contexte dans lequel les comportements des utilisateurs et des systèmes sont analysés afin de servir de fondement à la décision. L'exploitation de grands volumes de données de sécurité permet aux entreprises de « fouiller » l'ensemble de leur infrastructure pour accélérer les enquêtes a posteriori et améliorer la détection de fraudes, ainsi que la sécurité du SI dans son ensemble.
« De nombreux responsables de la sécurité informatique ont beaucoup de données à traiter et recherchent des personnes qui connaissent l'analytique. Ils ont également besoin d'analystes venant du décisionnel afin d'étudier les données de sécurité sans idées préconçues. L'objectif est de trouver des schémas logiques au milieu de toutes ces données », constate Mais Brian Fitzgerald, vice-président de RSA en charge du marketing.
- La santé : le Big Data peut aussi servir des causes plus « nobles » que la volonté d'être meilleur que les concurrents. Fin mars 2012, le Centre Hospitalier Universitaire de Leiden aux Pays-Bas a retenu Bull pour l'aider à concevoir un environnement de stockage Big Data. L'un des objectifs est de faciliter le calcul intensif sur des volumes de données gigantesques afin de disséquer et séquencer l'ADN humain.
De façon générale, les entreprises souhaitent bénéficier de méthodes d'analyse plus rapides et des rapports plus clairs et adaptés à leurs exigences (au fil de la journée ou de façon périodique) afin de disposer d'un avantage concurrentiel. Cette tendance a été identifiée par l'indice Big Data de Jaspersoft. Cet éditeur des logiciels décisionnels a mis en place en janvier 2012 le premier indice Big Data dans le secteur du décisionnel. Il s'agit d'un classement des connecteurs en téléchargement associés aux principales bases et sources de données.

« Recherche désespérément scientifique des données »
Malgré les progrès réalisés par les solutions de Big Data, l'être humain reste indispensable. Exceptées des solutions simplifiées à destination de PME, il ne s'agit pas de produits pré-packagés où il suffit d'ouvrir une boite, d'installer un logiciel sur des serveurs et le mettre en production. D'où la nécessité d'avoir des administrateurs systèmes avec des solides connaissances pratiques et surtout des... « scientifiques des données ».Ils doivent être capables de combiner les compétences d'un programmeur de logiciels et d'un statisticien et poser aussi les bonnes questions à la machine. En un mot, ils sont capables de faire le rapprochement entre les données brutes et leur analyse. Bref, un mouton à cinq pattes très difficile à dénicher. En plus de ce profil, les entreprises doivent disposer d'experts en mathématique et en statistique pour développer des modèles analytiques avancés et dégager des tendances... Cette carence apparaît d'ores et déjà comme un frein au développement du Big Data. Aux États-Unis, McKinsey prévoit un déficit de 140 000 à 190 000 spécialistes en analyse de données d'ici à 2018.
Big Data et protection des données personnelles
Selon la Commission nationale de l'informatique et des libertés (CNIL), le phénomène Big Data ne modifie pas en tant que tel la nature des obligations que les entreprises ont vis-à-vis des données personnelles (clients, fournisseurs, salariés) qu'elles détiennent. Le problème vient plutôt du fait que le volume devient de plus en plus important et donc de plus en plus difficiles à sécuriser.
Selon une enquête menée en 2010 par le Ponemon Institute auprès de 1000 spécialistes, 42 % considèrent que leur propre entreprise ne fait pas grand-chose pour réduire les risques de vols ou de pertes de données confidentielles. 45% d'entre eux reconnaissent qu'ils seraient dans l'impossibilité d'identifier, et donc d'avertir, les utilisateurs ou les clients dont les données personnelles auraient été volées.
Or l'article 34 de la Loi n° 78-17 du 6 janvier 1978 relative à l'informatique, aux fichiers et aux libertés précise : « Le responsable du traitement met en œuvre toutes mesures adéquates, au regard de la nature des données et des risques présentés par le traitement, pour assurer la sécurité des données et en particulier protéger les données à caractère personnel traitées contre toute violation entraînant accidentellement ou de manière illicite la destruction, la perte, l'altération, la divulgation, la diffusion, le stockage, le traitement ou l'accès non autorisés ou illicites ».
Selon la Commission nationale de l'informatique et des libertés (CNIL), le phénomène Big Data ne modifie pas en tant que tel la nature des obligations que les entreprises ont vis-à-vis des données personnelles (clients, fournisseurs, salariés) qu'elles détiennent. Le problème vient plutôt du fait que le volume devient de plus en plus important et donc de plus en plus difficiles à sécuriser.
Selon une enquête menée en 2010 par le Ponemon Institute auprès de 1000 spécialistes, 42 % considèrent que leur propre entreprise ne fait pas grand-chose pour réduire les risques de vols ou de pertes de données confidentielles. 45% d'entre eux reconnaissent qu'ils seraient dans l'impossibilité d'identifier, et donc d'avertir, les utilisateurs ou les clients dont les données personnelles auraient été volées.
Or l'article 34 de la Loi n° 78-17 du 6 janvier 1978 relative à l'informatique, aux fichiers et aux libertés précise : « Le responsable du traitement met en œuvre toutes mesures adéquates, au regard de la nature des données et des risques présentés par le traitement, pour assurer la sécurité des données et en particulier protéger les données à caractère personnel traitées contre toute violation entraînant accidentellement ou de manière illicite la destruction, la perte, l'altération, la divulgation, la diffusion, le stockage, le traitement ou l'accès non autorisés ou illicites ».
Les solutions dédiées au Big Data
Pour répondre aux trois défis (volume, variété et vélocité), les solutions de Big Data s'appuient principalement sur des moteurs de recherche développés pour le Business Search. Ces outils sont beaucoup plus efficaces et « intelligents » que Google dont les résultats s'appuient uniquement sur la popularité (d'un point de vue statistique) d'une information.Pour traiter ces gros volumes de données disparates, les éditeurs se sont tournés vers les appliances et trois types de technologies distinctes : une accélération matérielle à l'aide de mémoires dynamiques DRAM ou Flash, le recours à des bases de données massivement parallèles ou à des solutions utilisant des formats de bases de données non relationnelles basées sur NoSQL. Quelle que soit l'option retenue, l'objectif ne consiste pas simplement à interroger une base de données. Il s'agit d'effectuer des calculs d'analyses avancées pour obtenir de nouvelles informations à forte valeur ajoutée.
Au début du Big Data, « il y avait d'un coté les moteurs spécialisés qui offrent une optimisation maximale, via une structuration et un stockage des données en colonnes par exemple. Ils permettent des requêtes analytiques propices aux applications de type décisionnel. D'un autre coté, il y avait les moteurs de traitement de données de type Appliance MPP (Massive Parallel Procesing) qui sont davantage adaptés aux grands datawarehouses d'entreprise pour des usages aussi bien transverses que métiers. Ils centralisent le patrimoine d'informations de l'entreprise et autorisent une organisation des données relativement souple », rappelle Romain Chaumais.
Les bases de données NoSQL
L'un des points forts de cette solution est sa performance. Trois principaux atouts se détachent : la cohérence (visibilité par tous les nœuds d'un système des données identiques à un instant T), la haute disponibilité des données même en cas de panne et, enfin, la possibilité de partitionner tout système distribué. Les bases de données NoSQL ne sont donc pas une technologie de remplacement des SGBDR. Elles apportent simplement des options supplémentaires quant au mode de représentation de données utilisé pour un projet.
Les fournisseurs proposant des solutions basées sur NoSQL (Not Only SQL) sont de plus en plus nombreux. Parmi les moteurs noSQL les plus connus figurent MongoDB et Cassandra (open source), ou Caché (d'Intersystems). Ils y associent également le plus souvent le framework Open Source d'analyse de données en masse Hadoop, comme c'est le cas pour Microsoft et IBM. Mais également Oracle qui de son côté propose une appliance (boîtier) dédiée au Big Data reposant à la fois sur Hadoop mais aussi une version personnalisée de NoSQL.
MapReduce de Google
Le traitement des données est réparti sur une multitude de machines. Il s'agit d'un modèle d'exploitation « brute » des données. Il n'y a pas d'échantillonnage et l'approche est plus statistique qu'exhaustive. Mais l'univers MapReduce est complexe et difficile d'accès. L'implémentation de MapReduce la plus connue, en dehors de celle de Google, est Hadoop.
Hadoop, la référence Open source

Conçu par Doug Cutting (auteur également de Nutch, un projet de moteur de recherche libre) en 2004, Hadoop répond à deux besoins spécifiques :
- un traitement massif des données n'ayant pas de schéma clair et de leur transformation vers un format plus structuré.
- l'élaboration de modèles prédictifs (lutte contre la fraude, type de publicité à proposer en ligne...) dans des environnements changeants.
Hadoop de la fondation Apache (une organisation à but non lucratif créée en 1999) a contribué à modifier le modèle économique du Big Data. En moins de 4 ans, tout le monde ou presque (de Talend, Oracle, Teradata en passant par IBM et EMC) l'a adopté à cause principalement de son prix, de sa maturité, de sa rapidité (en mai 2009, Yahoo a trié 1 téraoctet de données en... 62 secondes) et de sa flexibilité.
Toutes les solutions propriétaires l'intègrent. Le rôle des éditeurs consiste donc à proposer des briques complémentaires (administration, monitoring, sécurité...) devant interagir autour de ce même noyau ouvert. L'écosystème Hadoop se renforce de jour en jour avec l'arrivée de nouveaux intégrateurs et éditeurs. Selon une étude publiée début mai 2012 par IDC, les levées de fonds autour de Hadoop et MapReduce ont atteint environ 300 millions de dollars.
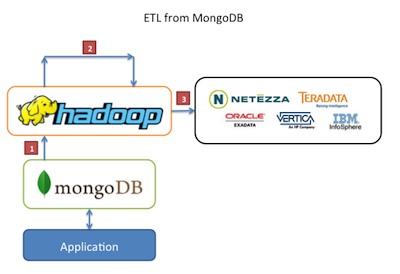
Schéma extraction / chargement de données via Hadoop et MongoDB, une base NoSQL
Et cette tendance ne devrait pas s'atténuer avant 2016 selon cette même analyse. Le cabinet IDC estime en effet que le marché de Hadoop et MapReduce devrait croître de plus de 60% par an jusqu'en 2016 pour s'établir à presque 813 millions de dollars à cette date. Le « Hadoop native » reste donc incontournable.
Des offres Big Data en SaaS (Software as a Service)
La mutualisation des ressources permet de réduire les coûts. Il est désormais possible de mettre en place des applications Big Data en quelques semaines seulement. C'est le cas avec la technologie de Squid Solutions qui exploite au maximum les fonctions avancées de la base de données massivement parallèle EMC Greenplum en réalisant ses calculs « in-database », directement sur les données brutes, pour accélérer la création et le déploiement de Business Applications innovantes.
La mutualisation des ressources permet de réduire les coûts. Il est désormais possible de mettre en place des applications Big Data en quelques semaines seulement. C'est le cas avec la technologie de Squid Solutions qui exploite au maximum les fonctions avancées de la base de données massivement parallèle EMC Greenplum en réalisant ses calculs « in-database », directement sur les données brutes, pour accélérer la création et le déploiement de Business Applications innovantes.
Quelques grands acteurs du Big Data
Les fournisseurs de solutions ont commencé à élaborer leurs offres à la fin des années 2000 et le mouvement s'est accéléré ces derniers temps avec l'arrivée sur ce créneau d'acteurs historiques comme Oracle, IBM ou, plus récemment, Microsoft. Ces derniers ont d'ailleurs investi plus de 15 milliards de dollars pour acheter des entreprises de logiciels spécialisées dans la gestion et l'analyse de données. En juin 2011, Informatica, acteur dans le domaine de l'intégration de données, a également annoncé son offre.Comme le rappelle l'étude d'IDC citée à propos de Hadoop, le marché du Big Data est en pleine croissance et la majorité des offres s'articulent autour d'Hadoop. L' « hégémonie » du framework de la Fondation Apache et de MapReduce reste une évidence.
Sinequa, la référence française ?
Classée par le magazine EContent parmi les 100 entreprises qui comptent le plus pour la 3e année consécutive, Sinequa vient également d'être honoré d'un Trend Setting Product 2011 décerné par le magazine KM World. Pour s'imposer dans le Business Search, l'entreprise mise sur l'innovation. « Nous avons un principe : toutes les réponses doivent s'afficher en dessous de la seconde quel que soit le type de recherche. Si le volume de données à analyser est trop important, nous ajoutons deux machines, etc. (architecture grid) », explique Alexandre Bilger, PDG de Sinequa.
Concernant le Big Data, le PDG de Sinequa rappelle l'importance de la structuration de l'information : « les données qui sont sur le Web ou dans l'entreprise ont une certaine structure. Si on veut analyser de manière massive ces données ou les présenter de manière intelligente à l'utilisateur, il faut les structurer en utilisant tous les moyens disponibles informatiquement (statistique, linguistique et sémantique). En combinant ces éléments, nous sommes capables de faire émerger cette structure qui n'existe pas a priori. »
Classée par le magazine EContent parmi les 100 entreprises qui comptent le plus pour la 3e année consécutive, Sinequa vient également d'être honoré d'un Trend Setting Product 2011 décerné par le magazine KM World. Pour s'imposer dans le Business Search, l'entreprise mise sur l'innovation. « Nous avons un principe : toutes les réponses doivent s'afficher en dessous de la seconde quel que soit le type de recherche. Si le volume de données à analyser est trop important, nous ajoutons deux machines, etc. (architecture grid) », explique Alexandre Bilger, PDG de Sinequa.
Concernant le Big Data, le PDG de Sinequa rappelle l'importance de la structuration de l'information : « les données qui sont sur le Web ou dans l'entreprise ont une certaine structure. Si on veut analyser de manière massive ces données ou les présenter de manière intelligente à l'utilisateur, il faut les structurer en utilisant tous les moyens disponibles informatiquement (statistique, linguistique et sémantique). En combinant ces éléments, nous sommes capables de faire émerger cette structure qui n'existe pas a priori. »
Amazon
Le poids lourd du e-commerce américain a démocratisé le Big Data avec l'avènement du Cloud Computing. Il propose depuis avril 2009 Amazon Web Services et Elastic MapReduce (EMR). EMR permet l'exploration de données instantanément, sans se soucier de l'installation, de la gestion ou de l'ajustement des clusters Hadoop. Trier et dénicher des informations pertinentes devient donc à la portée de toutes les entreprises selon Amazon. « Jusqu'à encore récemment, il aurait fallu des années pour analyser un ensemble de 21 millions de composés chimiques avec une petite instance HPC intégrant quelques centaines de cœurs ». Grâce au supercalculateur de Cycle Computing, ses tests ne prennent plus que trois heures « Ce supercalculateur de 50 000 cœurs est immédiatement accessible pour 5000 dollars de l'heure. Cela signifie aussi qu'il est disponible pour tout le monde », déclare Werner Vogels, CTO d'Amazon.
Le moteur de recherche a été l'un des précurseurs du Big Data en développant MapReduce dès 2004. Schématiquement, les deux termes peuvent être présentés de la façon suivante.
-Map : établir un couple (clé, valeur) pour chaque élément de données.
- Reduce : agréger, résumer, filtrer ou transformer les données.
Pour Google, les principales applications sont l'indexation du web, l'analyse d'images satellites et les calculs statistiques pour Google translate. Ses principaux avantages sont la parallélisation automatique, l'équilibrage de charge, l'optimisation sur les transferts disques et réseaux et la tolérance aux pannes. Des librairies MapReduce existent pour C++, C#,Erlang, Java, Python, Ruby...
IBM
Comme beaucoup d'autres acteurs du secteur, IBM a conçu des briques s'intégrant à Hadoop, HDFS et le framework MapReduce. Depuis fin 2011, il propose InfoSphere BigInsights Basic pour IBM SmartCloud Enterprise. La version Basic, qui peut gérer jusqu'à 10 To de données, est disponible gratuitement pour les systèmes Linux. Par contre, BigInsights Enterprise reste payant. Big Blue continue aussi à acheter des sociétés spécialisées dans la collecte, la capture et l'organisation de l'information et des données multisources, multiformats et multiplateformes. Dernière acquisition en date : Vivisimo, en avril 2012. Elle revendique quelque 140 clients dans le secteur public, la recherche, l'industrie, l'électronique et les secteurs financiers. Airbus, l'US Airforce et l'US Navy en sont utilisateurs.

Microsoft
Fin 2011, le géant de l'informatique a finalement privilégié la raison, en abandonnant LINQ to HPC pour tout mettre sur Hadoop. L'éditeur de Redmond a signé un accord avec Hortonworks (voir ci-dessous avec Yahoo!) afin de porter le framework java sur Windows Server et Windows Azure. Le Big Data est par ailleurs l'un des enjeux majeurs auxquels souhaite répondre Microsoft avec la dernière version de son logiciel de gestion de bases de données, SQL Server 2012.
Yahoo!
Il est devenu le principal contributeur au projet Hadoop (avec des estimations tablant sur 70% du code produit) après avoir embauché son créateur, Doug Cutting, en janvier 2006. Cinq ans plus tard, Yahoo! a confirmé son intérêt pour ce framework en officialisant la création de Hortonworks, une entreprise indépendante. Financée par le portail et le fonds d'investissement Benchmark Capital, elle est entièrement dédiée au développement et au support du framework open source.
Vmware
Le leader mondial de la virtualisation et des infrastructures de Cloud Computing, propose SpringHadoop, dernier né de la suite de projets Spring Data. « VMware s'appuie sur l'expérience forte et polyvalente de Spring autour de la simplification de l'accès aux données et tire parti de la plate-forme complète Hadoop pour livrer un modèle de programmation rationalisé faisant de Spring la méthode naturelle d'intégration des systèmes Hadoop au sein du paysage applicatif de l'entreprise », justifie l'éditeur. Comme IBM, WMware continue aussi ses emplettes. Fin avril, il a acquis la jeune entreprise californienne Cetas. Créée il y a 18 mois, elle propose une solution analytique de données (placées dans le cloud ou en interne) baptisée Instant Intelligence.
Le Big Data à la portée des PME
Pour l'instant, ces technologies s'adressent en priorité aux grands comptes et aux poids lourds du web. Mais de petites entreprises peuvent aussi en bénéficier. « Ces applications étaient impossibles à des coûts raisonnables il y a deux ans. Aujourd'hui, les PME peuvent se les offrir », affirme Isabelle Carcassonne, directeur marketing business & analytics optimization chez IBM.
Aux États-Unis, toutes les start-ups ont intégré le Big Data dans le développement de leur business. En France, seules les start-ups dans les jeux vidéos et les réseaux sociaux notamment testent cette solution. Une PME proposant des jeux sur Facebook a eu recours au Big Data pour comprendre comment un joueur devient addictif. Une analyse a conclu que cet internaute basculait quand au moins dix de ses amis virtuels jouent au même jeu. La stratégie de l'éditeur a été adaptée en conséquence.
La situation devrait rapidement évoluer avec l'arrivée de nouvelles solutions. « Le Big Data va de paire avec une autre évolution : le Cloud Computing. L'informatique dans les nuages permet d'accéder à des ressources importantes en mode "on demand". De plus en plus d'offres proposent ce genre de services. L'exemple le plus récent est Big Query. Proposé par Google, cet outil permet de traiter de gros volumes de données. Les coûts deviennent abordables pour identifier une information intéressante. Par exemple, l'analyse de 500 Go de données par cinq machines pendant 5 heures revient environ à 200 euros. Ce nouveau modèle économique permet aux PME de profiter des avantages du Big Data », explique Romain Chaumais, co-fondateur de Ysance, une société spécialisée dans l'intégration de solutions innovantes (notamment la Business Intelligence, ou informatique décisionnelle).
Pour l'instant, ces technologies s'adressent en priorité aux grands comptes et aux poids lourds du web. Mais de petites entreprises peuvent aussi en bénéficier. « Ces applications étaient impossibles à des coûts raisonnables il y a deux ans. Aujourd'hui, les PME peuvent se les offrir », affirme Isabelle Carcassonne, directeur marketing business & analytics optimization chez IBM.
Aux États-Unis, toutes les start-ups ont intégré le Big Data dans le développement de leur business. En France, seules les start-ups dans les jeux vidéos et les réseaux sociaux notamment testent cette solution. Une PME proposant des jeux sur Facebook a eu recours au Big Data pour comprendre comment un joueur devient addictif. Une analyse a conclu que cet internaute basculait quand au moins dix de ses amis virtuels jouent au même jeu. La stratégie de l'éditeur a été adaptée en conséquence.
La situation devrait rapidement évoluer avec l'arrivée de nouvelles solutions. « Le Big Data va de paire avec une autre évolution : le Cloud Computing. L'informatique dans les nuages permet d'accéder à des ressources importantes en mode "on demand". De plus en plus d'offres proposent ce genre de services. L'exemple le plus récent est Big Query. Proposé par Google, cet outil permet de traiter de gros volumes de données. Les coûts deviennent abordables pour identifier une information intéressante. Par exemple, l'analyse de 500 Go de données par cinq machines pendant 5 heures revient environ à 200 euros. Ce nouveau modèle économique permet aux PME de profiter des avantages du Big Data », explique Romain Chaumais, co-fondateur de Ysance, une société spécialisée dans l'intégration de solutions innovantes (notamment la Business Intelligence, ou informatique décisionnelle).
