

Après Code Interpreter, DALL-E 3, Bing et les plugins, ChatGPT se dote d'un nouveau modèle. Ce nouveau modèle, c'est ChatGPT 4 Vision, un modèle de reconnaissance d'images basé sur la version 4 de GPT. Ce modèle permet l'ajout d'images dans les conversations avec ChatGPT, pour qu'il puisse les analyser et fournir des informations sur celles-ci. Les cas d'usage sont très vastes, au point que les possibilités soient quasi illimitées.
Dans un monde où le visuel prend une place prépondérante, la capacité de comprendre et d'interpréter des images devient essentielle. GPT-4V, la dernière innovation d'OpenAI, fusionne le traitement du langage naturel avec la vision par ordinateur, offrant une nouvelle dimension à l'intelligence artificielle.
GPT-4V, c’est quoi ?
GPT-4V est une extension du modèle GPT-4, développé par OpenAI. Alors que GPT-4 est principalement axé sur la compréhension et la génération de texte, GPT-4V ajoute une nouvelle dimension : la capacité de comprendre et d'interagir avec des images. Cette avancée est rendue possible grâce à l'intégration de modèles de vision par ordinateur, qui permettent au modèle de traiter des données visuelles en plus des données textuelles.
En mars 2023, Be My Eyes et OpenAI ont travaillé ensemble pour créer Be My AI, une nouvelle fonction qui permet de décrire le monde visuel aux personnes aveugles et malvoyantes. Grâce à l'intégration de GPT-4 V dans la plateforme de Be My Eyes, les utilisateurs aveugles peuvent utiliser leur smartphone pour obtenir des descriptions de photos. Les résultats du test bêta ont révélé que Be My AI peut répondre aux besoins d'information, culturels et professionnels des utilisateurs aveugles et malvoyants en leur fournissant des outils sans précédent. De ce succès est né GPT-4V, d'abord disponible sous la forme d'une API. Ce nouveau modèle a plus récemment intégré ChatGPT au sein de l'offre Plus.
GPT-4V fonctionne de manière comparable à GPT-4. Tout comme Google Bard, il peut identifier des images avec ou sans une requête spécifique. Pour y accéder, il faudra ChatGPT Plus (20 $ par mois).
Comment utiliser GPT-4V ?
GPT-4V fonctionne de manière comparable à GPT-4. Tout comme Google Bard, il peut identifier des images avec ou sans une requête spécifique. Pour y accéder, il faudra ChatGPT Plus (20 $ par mois). Pour y accéder, il suffira de cliquer sur la petite icône image à côté du formulaire d'entrée pour vos requêtes et de selectionner une image parmis les votres.

GPT-4V a été formé sur un vaste ensemble de données qui comprend à la fois du texte et des images. L'entraînement du modèle utilise des techniques d'apprentissage supervisé et non supervisé pour optimiser la précision et la pertinence des réponses générées.

Les usages sont multiples. Par exemple, il peut identifier des objets dans une image, lire du texte incrusté et même comprendre des concepts abstraits comme l'émotion ou l'intention. Cette interaction texte-image est rendue possible grâce à des algorithmes de vision par ordinateur qui ont été intégrés dans l'architecture du modèle.

Quelles sont les limitations de GPT-4V ?
Bien que GPT-4V soit une avancée significative, il présente certaines limitations. Tout d'abord, le modèle, bien qu'impressionnant, n'est pas parfait peut parfois générer des réponses inexactes ou trompeuses. De plus, sa compréhension du contexte peut être limitée, ce qui peut entraîner des erreurs d'interprétation. Le modèle n'est pas adapté pour des applications médicales spécialisées comme l'interprétation de scanners CT, et il peut avoir des difficultés avec des tâches nécessitant une localisation spatiale précise ou la compréhension de textes en alphabets non-latins. De plus, il peut mal interpréter des images ou des textes tournés, et il peut générer des descriptions ou des légendes inexactes dans certains contextes.
D'autres limitations incluent des difficultés à traiter des éléments visuels complexes comme des graphiques ou des textes où les styles varient. Le modèle redimensionne également les images avant l'analyse, ce qui peut affecter leurs dimensions originales, et il ne traite pas les métadonnées ou les noms de fichiers originaux. Pour les images contenant plusieurs objets, le modèle peut fournir des comptages approximatifs. Enfin, le modèle se montrera plus réticent à analyser et interagir avec des photos de personnes pour des raisons évidentes (tout particulièrement la reconnaissance faciale).
Sur un plan plus technique, le poids de l'image téléversée sera limité à 20 MB. Pour ce qui est des formats pris en charge, on trouve les classiques PNG, JPEG ainsi que les GIF non-animés (oui ça existe !).

Quels sont les meilleurs cas d’usages de GPT-4V ?
GPT-4V, avec sa capacité à comprendre et interagir avec des images, ouvre la voie à une multitude d'applications innovantes et utiles. Nous l'avons mis sur le banc d'essai.
Comprendre une image satirique ou un cartoon
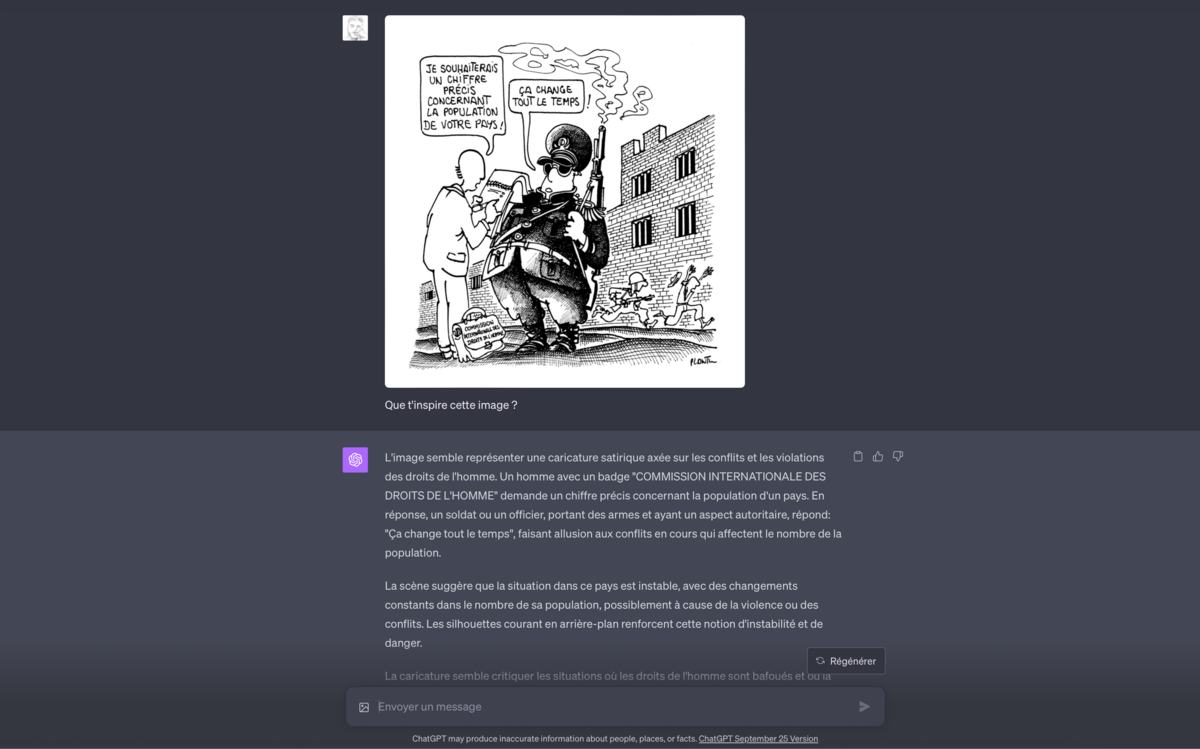

Vision peut comprendre l'humour caricatural de la même manière qu'une blague textuelle. Le dessin de Plantu qu'il a vu est clairement compréhensible pour lui et il saisit ses nuances. Nous avons même essayé de découvrir qui a fait ce dessin en demandant directement à Vision, mais il a répondu non sans équivoque, possiblement à cause des limitations exposées plus tôt. En revanche, une requête un peu plus détournée demandant d'identifier le signataire du dessin donne un résultat plus factuel.
Créer un site web à partir d'un mockup

Moins convaincant, le résultat reste intéressant et pourrait très certainement être amélioré un mockup plus détaillé et une requête optimisée.

Demander de l'aide sur une tâche ménagère

Que ce soit pour monter un meuble ou pour comprendre les instructions d'un appareil électroménager, GPT-4V peut aider en fournissant des instructions étape par étape basées sur une photo de l'objet ou du manuel. Ici, nous lui avons demandé de l'aide sur une tâche ménagère simple mais sans contexte : nettoyer une plaque de cuisson. Vision détecte de lui-même qu'il s'agit d'une plaque de cuisson en céramique et identifie immédiatement le type de tâche dont il s'agit. Il va ensuite nous lister les différentes méthodes pour nettoyer et prévenir de futures tâches.
GPT-4V marque une étape décisive dans le développement de ChatGPT. C'est un pas de géant vers un modèle multimodale qui sera capable de comprendre image, son, texte, vidéo et d'autres formes d'entrées. GPT-5 ne semblant pas arriver de sitôt, ces nouveautés sont la bienvenue et ouvrent un nouveau champ des possibles pour les utilisateurs, qu'il s'agisse de professionnels ou non.

- Chat dans différentes langues, dont le français
- Générer, traduire et obtenir un résumé de texte
- Générer, optimiser et corriger du code





