

Le deepfake qui a remplacé Robert Downey Jr par Tom Cruise dans le rôle d'Iron Man © Collider Video
Une équipe de chercheurs de l'université de San Diego dit être parvenue à tromper, de manière relativement simple, les systèmes de détection des deepfakes, ces vidéos « truquées » par une intelligence artificielle.
Le projet sonne comme un avertissement alors que ce type de contenus s'est considérablement développé ces dernières années.
Perturbations vidéo
Les résultats ont été publiés sur le site de l'université de Cornell. L'équipe parle de « deepfakes perturbatoires », qu'elle définit comme des vidéos « intentionnellement perturbées pour tromper un modèle de classification ». La publication précise : « Dans ce projet, nous démontrons qu'il est possible de contourner (les) détecteurs en modifiant de fausses vidéos utilisant des méthodes déjà existantes de création de deepfakes ». Elle ajoute : « Nous démontrons en outre que nos perturbations sont robustes aux codecs de compression d'image et de vidéo, ce qui en fait une menace réelle ».Les universitaires ont utilisé des vidéos de deepfakes et leur ont ajouté des « perturbations » (comme du bruit gaussien), si l'on en croit l'infographie issue de l'étude ci-dessous. Si cet ajout doit être réalisé selon une certaine méthode de calcul, une fois celui-ci terminé, l'image semble identique pour un être humain, mais pas pour les logiciels de détection, qui estiment désormais que la vidéo est authentique.
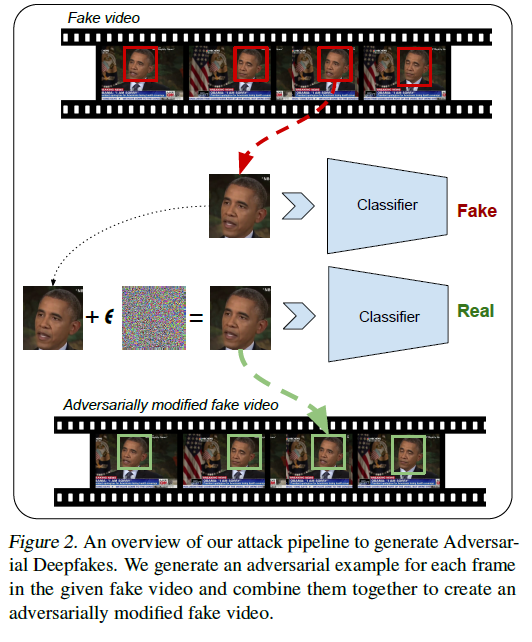
© UC San Diego
Lire aussi :
Facebook lance le Deepfake Detection Challenge, pour améliorer la détection des vidéos truquées
Facebook lance le Deepfake Detection Challenge, pour améliorer la détection des vidéos truquées
Soulever le problème
Les chercheurs précisent que leur méthode a réussi à tromper deux logiciels de détection baptisés XceptionNet et MesoNet, tous deux basés sur le modèle « CNN » (Convolutional Neural Networks). Ils déclarent : « Ces détecteurs [...] fonctionnent par image et classent chaque image indépendamment en tant que réel ou fausse ». Bien que simple, le procédé a permis de tromper des intelligences artificielles dont le fonctionnement était connu publiquement (IA de type white-box), et d'autres dont le fonctionnement était inconnu (type black-box).Les résultats de l'étude sont fournis en exemples. L'infographie ci-dessus a montré le résultat obtenu sur une interview de l'ancien Président américain Barack Obama. Ci-dessous, les chercheurs fournissent les résultats obtenus pour d'autres images, choisies aléatoirement. Les auteurs précisent qu'à chaque fois, la colonne de gauche montre le deepfake d'origine, qui a été reconnu comme tel par le logiciel de détection. Les autres colonnes montrent des images qui, a priori, semblent identiques, mais auxquelles des perturbations ont été ajoutées et ont été reconnues comme « authentiques » par les logiciels.

© UC San Diego
Pour ses auteurs, l'étude prouve que la méthode actuellement utilisée pour la détection de deepfakes doit encore être améliorée. Les scientifiques ont déclaré : « Nous voulons soulever explicitement ce problème qui a été ignoré par les travaux existants sur la détection de deepfakes [...]. Étant donné que la génération de fausses vidéos peut potentiellement être utilisée à des fins malveillantes, il est essentiel de remédier à la vulnérabilité des détecteurs de deepfakes aux entrées perturbatoires ».
Source : Medium









